Guia mais simples para fazer seu próprio brinquedo LLM em 2024

2024 está aqui, e brinquedos DIY LLM? Totalmente uma coisa agora. Não é necessária magia tecnológica, apenas sua curiosidade. Eu tomei a mergulha, misturando um pouco de codificação com montes de diversão, e bam — criei meu próprio brinquedo falante. Se você está pronto para criar um amigo de IA com facilidade, você está no lugar certo. Vamos desmistificar a tecnologia juntos e dar vida ao seu amigo de IA. Em um mundo onde a tecnologia se cruza cada vez mais com a vida diária, criar seu próprio brinquedo LLM não apenas desmistifica a IA, mas também fornece uma porta de entrada personalizada para as maravilhas da tecnologia interativa.
Vamos dar uma olhada no efeito final primeiro.
Honestamente, é muito incrível. Pronto para começar? Vamos mergulhar!
Como Funciona?
Existem três etapas principais:
- Gravação: Receba dados de gravação em tempo real enviados pelo brinquedo através do UDP e chame a API STT (Sound-To-Text) para converter o som em texto.
- Pensando: Depois de receber o texto anterior, a API LLM (Large-Language-Model) será imediatamente chamada para obter frases geradas pelo LLM de maneira de streaming. Em seguida, a API TTS (Text-To-Sound) é chamada para converter as frases em fala humana.
- Reproduzir áudio: Os brinquedos receberão fluxos de arquivos de áudio TTS (Text-To-Sound) gerados pelo Servidor FoloToy e os reproduzirá de acordo com a ordem.
Preparação Antes do Desenvolvimento
Antes de começar a fazer seu brinquedo LLM, é crucial entender o hardware, software e conhecimento técnico necessários. Esta seção irá guiá-lo na preparação de todos os itens essenciais para garantir um início tranquilo.
Hardware

Folotoy Core: O ChatGPT AI Voice Conversation Core Board serve como o cérebro do seu projeto, permitindo interações de voz com a IA.

Componentes de brinquedo: itens essenciais como microfone, alto-falante, botões, interruptores e fonte de alimentação são necessários. Eu vou com o Alilo Honey Bunny G6 por sua configuração pronta para uso.

Terno De Desenvolvimento De Polvo (Outra escolha): Ideal para aqueles que procuram adaptar os brinquedos existentes com recursos de IA.
Ao fazer uma compra, forneça meu código promocional F-001–9 para receber um desconto.
Servidor
Utilizando sua própria máquina, como um MacBook Pro, garantindo que seu brinquedo tenha um back-end confiável para processar e responder às interações de voz. Alternativamente, serviços em nuvem como o Google Cloud Engine (GCE) podem dimensionar seu projeto para aplicativos mais amplos.
Conhecimento
- Docker (obrigatório): Compreender o Docker é crucial para implantar software em contêineres, tornando seu projeto portátil e escalável. Eu o uso para iniciar o servidor Folo.
- Git (obrigatório): O controle de versão é essencial para gerenciar a base de código do seu projeto. Eu o uso para gerenciar a base de código do servidor Folo.
- MQTT (opcional): Se você está visando uma personalização avançada, a familiaridade com o MQTT (um protocolo de mensagens leve) será benéfica para a comunicação entre o brinquedo e o servidor.
- EMQX (opcional): Corretor MQTT de código aberto para IoT, IIoT e veículos conectados. Usado para gerenciar seus brinquedos.
- ollama (opcional): Se você quiser executar modelos de idiomas grandes localmente, é uma boa escolha.
Serviços e Registro
Para dar vida ao seu brinquedo, você precisará de acesso a serviços específicos de IA. Para este projeto, optei por utilizar as ofertas da OpenAI:
- TTS (Text-to-Speech): O serviço Whisper da OpenAI converte respostas de texto da IA em fala, tornando a interação natural.
- LLM (Large Language Model): Utilizando os modelos da OpenAI para entender e gerar respostas de texto semelhantes a humanos.
- STT (Speech-to-Text): O serviço TTS da OpenAI transcreve palavras faladas em texto, permitindo que a IA entenda comandos ou consultas de voz.
O mais importante é que você precisa se registrar na plataforma OpenAI e criar uma chave, como sk-...i7TL.
Monte Seu Brinquedo
Agora é hora de juntar todas as peças e fazer seu próprio brinquedo LLM.
As etapas gerais são as seguintes, recomenda-se assistir ao vídeo tutorial primeiro.
- Verifique se a gravação e a reprodução do Alilo G6 são normais.
- Use uma chave de fenda para desaparafusar os 6 parafusos na parte de trás do Alilo G6.
- Abra cuidadosamente a caixa do Alilo G6, desconecte todos os plugues da placa-mãe, primeiro desconecte o plugue de alimentação, há cola no plugue, você pode usar uma faca de arte para cortá-lo suavemente, certifique-se de não cortar a mão.
- Desenrosce os 4 parafusos da placa-mãe e remova-a.
- Substitua a placa-mãe original pela placa-mãe da FoloToy e aperte 3 parafusos para consertá-la.
- Conecte o microfone, a luz, o alto-falante e as tomadas de energia, finalmente conecte a tomada de energia.
- Depois de conectar todos os soquetes, ainda não feche a caixa ou instale os parafusos. Primeiro ligue/desligue o interruptor na cauda do coelho para ver se a luz recém-instalada pode ligar e piscar lentamente na cor azul.
- Se não houver problema, instale a carcaça e aperte os parafusos para concluir o processo de substituição.
Configure o Servidor
Um forte suporte de back-end é fundamental para fazer com que seus brinquedos LLM entendam e respondam a comandos de voz. Esta seção ensinará como clonar a base de código do servidor, configurar o servidor e iniciar contêineres Docker para garantir que seus brinquedos tenham suporte de back-end estável.
Primeiro clone a base de código do servidor Folo do GitHub.
git clone [email protected]:FoloToy/folotoy-server-self-hosting.git
Em seguida, altere a configuração do servidor base no arquivo docker-compose.yml para o seu próprio.
| Nome | Descrição | Exemplo |
|---|---|---|
| OPENAI_OPENAI_KEY | Sua chave de API OpenAI. | sk-...i7TL |
| OPENAI_TTS_KEY | Sua chave de API OpenAI. | sk-...i7TL |
| OPENAI_WHISPER_KEY | Sua chave de API OpenAI. | sk-...i7TL |
| AUDIO_DOWNLOAD_URL | A URL do arquivo de áudio. | http://192.168.x.x:8082 |
| SPEECH_UDP_SERVER_HOST | O endereço IP do seu servidor. | 192.168.x.x |
Em seguida, configure suas funções no arquivo config/roles.json, aqui está um exemplo mínimo, para configuração completa, consulte a documentação Folotoy.
{
"1": {
"start_text": "Olá, o que posso fazer por você?",
"prompt": "You are a helpful assistant."
}
}
Em seguida, inicie os contêineres Docker.
docker compose up -d
Eu executo o servidor Folo na minha própria máquina, se você quiser executá-lo na nuvem, quase o mesmo. Uma coisa a notar é que você precisa expor a porta 1883, 8082, 8085, 18083 e 8083 à rede pública.
Para mais informações, consulte a documentação Folotoy.
Converse com seu brinquedo
Quando tudo estiver pronto, é hora de interagir com seu brinquedo LLM.
Ligue o interruptor na parte de trás do brinquedo para ligá-lo. A luz azul piscando nos ouvidos indica que o brinquedo entrou no modo de emparelhamento.
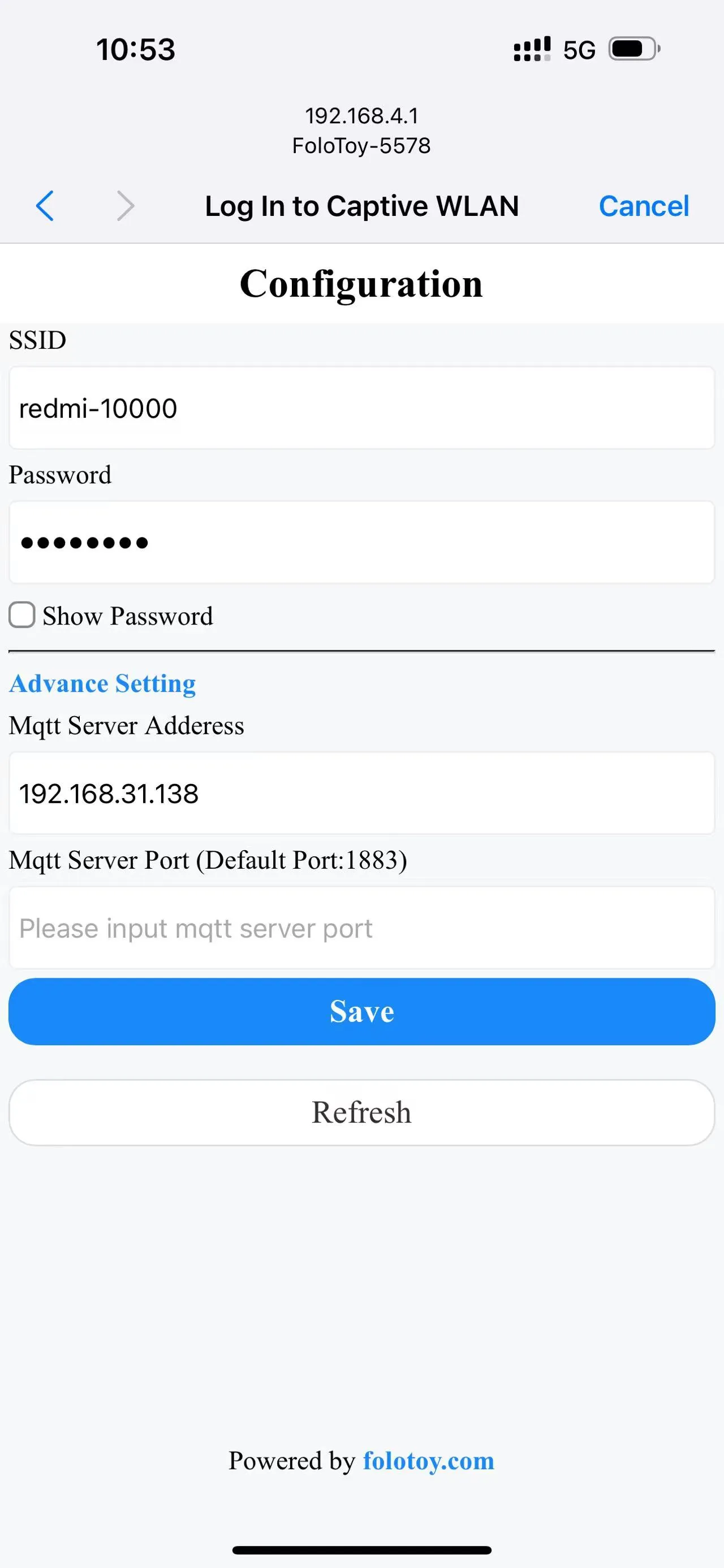
Ligue seu telefone ou computador e selecione a rede sem fio "FoloToy-xxxx". Depois de um momento, seu telefone ou computador abrirá automaticamente uma página de configuração onde você pode definir a qual rede WiFi (SSID e senha) se conectar, bem como o endereço do servidor (como 192.168.x.x) e o número da porta (mantenha o padrão 1883).

Depois que a rede estiver configurada e conectada ao servidor, pressione o grande botão redondo no meio para iniciar a conversa. Depois que você parar de falar, FoloToy emitirá um bipe para indicar o fim da gravação.
Os 7 pequenos botões redondos ao redor são botões de troca de função. Depois de clicar, a troca de função entra em vigor.
Depuração
Seja um servidor ou um brinquedo, você pode encontrar alguns problemas técnicos. Esta seção fornecerá algumas dicas e ferramentas básicas de depuração para ajudá-lo a diagnosticar e resolver possíveis problemas e garantir que seus brinquedos LLM possam funcionar sem problemas.
Depuração do Servidor
Para verificar os registros do servidor, execute o seguinte comando.
docker compose logs -f
LOG_LEVEL pode ser definido no arquivo docker-compose.yml para controlar o nível de log.
Depuração de Brinquedos
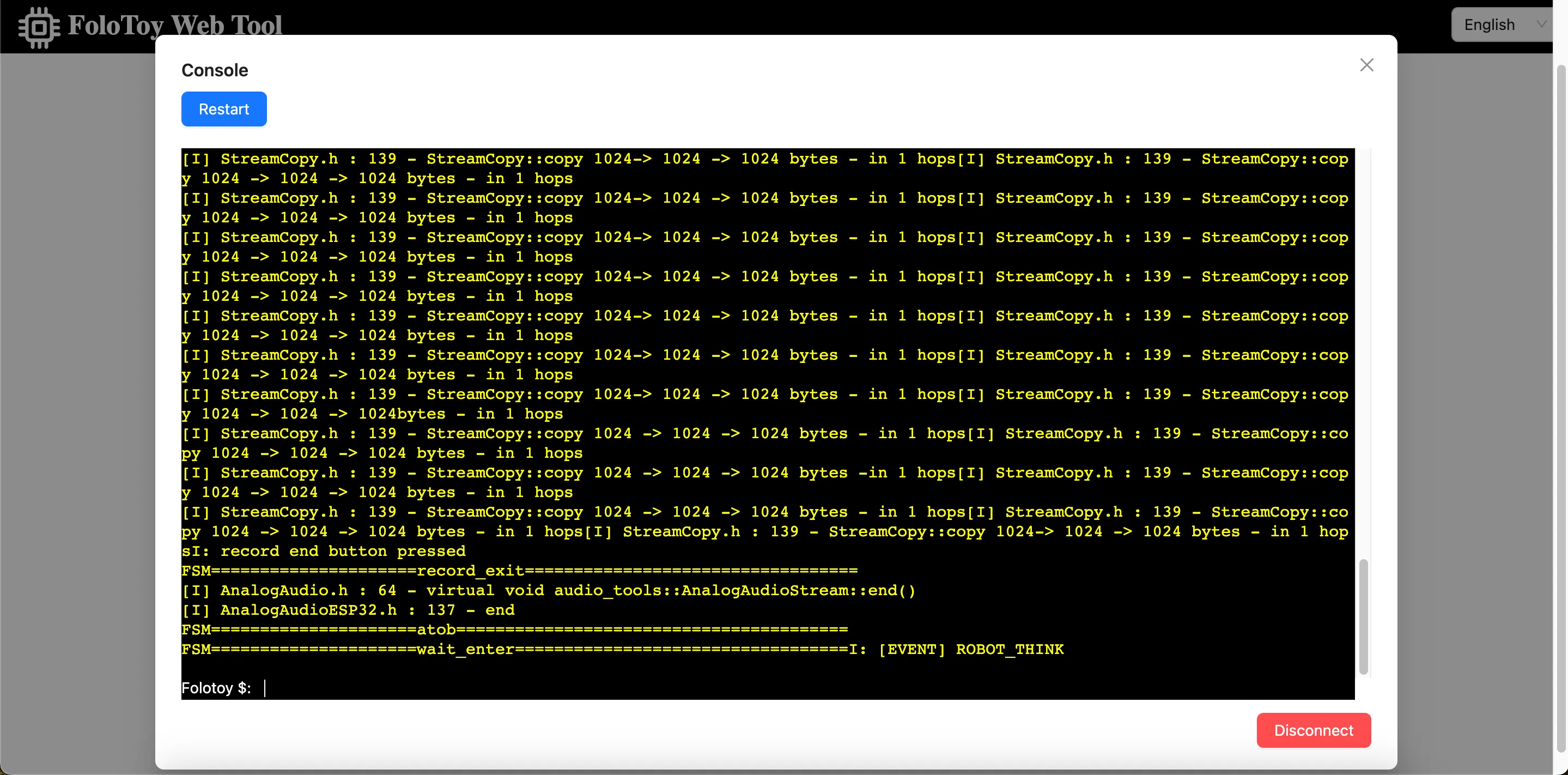
O Folo Toy fornece uma maneira fácil de depurar a base do brinquedo na porta serial USB. Você pode usar a Folo Toy Web Tool para depurar o brinquedo.
- Conecte o brinquedo ao seu computador usando um cabo USB.
- Abra a Ferramenta Web Folo Toy e clique no botão "Console" para se conectar ao brinquedo.
- Uma vez conectado, você deve ser capaz de ver os registros em tempo real do seu dispositivo no console.
Também há um LED no brinquedo, ele acenderá em cores diferentes para indicar o status do brinquedo.
Depuração MQTT
Abra o EMQX Dashboard para verificar as mensagens MQTT. O nome de usuário padrão é admin e a senha é public. De qualquer forma, altere a senha para uma segura depois de fazer login.
Personalização Avançada
Para usuários avançados que desejam explorar e personalizar ainda mais seus brinquedos LLM, esta seção apresentará como executar localmente modelos de linguagem grandes, usar ferramentas como o CloudFlare AI Gateway e personalizar a voz dos personagens. Isso abrirá um mundo mais amplo de brinquedos DIY LLM para você.
Execute LLM Localmente

Executar modelos de linguagem grande localmente é uma coisa interessante. Você pode executar Llama 2, Gemma e todos os tipos de modelos grandes de código aberto de todo o mundo, até mesmo modelos treinados por você mesmo. Usando ollama, você pode fazer isso facilmente. Instale ollama primeiro e, em seguida, execute o seguinte comando para executar o modelo Llama 2.
ollama run llama2
Em seguida, altere a configuração da função para usar o modelo LLM local.
{
"1": {
"start_text": "Olá, o que posso fazer por você?",
"prompt": "You are a helpful assistant.",
"llm_type": "ollama",
"llm_config": {
"api_base": "http://host.docker.internal:11434",
"model": "llama2"
}
}
}
O api_base deve ser o endereço do endereço do seu servidor ollama, e não se esqueça de reiniciar o servidor Folo para que as alterações entrem em vigor.
docker compose restart folotoy
Isso é tudo, mude o modelo para Gemma ou outros modelos como quiser, e aproveite.
Use o CloudFlare AI Gateway
O AI Gateway da Cloudflare permite que você ganhe visibilidade e controle sobre seus aplicativos de IA. Ao conectar seus aplicativos ao AI Gateway, você pode coletar insights sobre como as pessoas estão usando seu aplicativo com análises e registro e, em seguida, controlar como seu aplicativo se dimensiona com recursos como cache, limitação de taxa, bem como tentativas de solicitação, fallback de modelo e muito mais.
Primeiro, você precisa criar um novo Gateway de IA.
Em seguida, edite o arquivo docker-compose.yml para alterar OPENAI_OPENAI_API_BASE para o endereço do seu AI Gateway, assim:
services:
folotoy:
environment: OPENAI_OPENAI_API_BASE=https://gateway.ai.cloudflare.com/v1/${ACCOUNT_TAG}/${GATEWAY}/openai
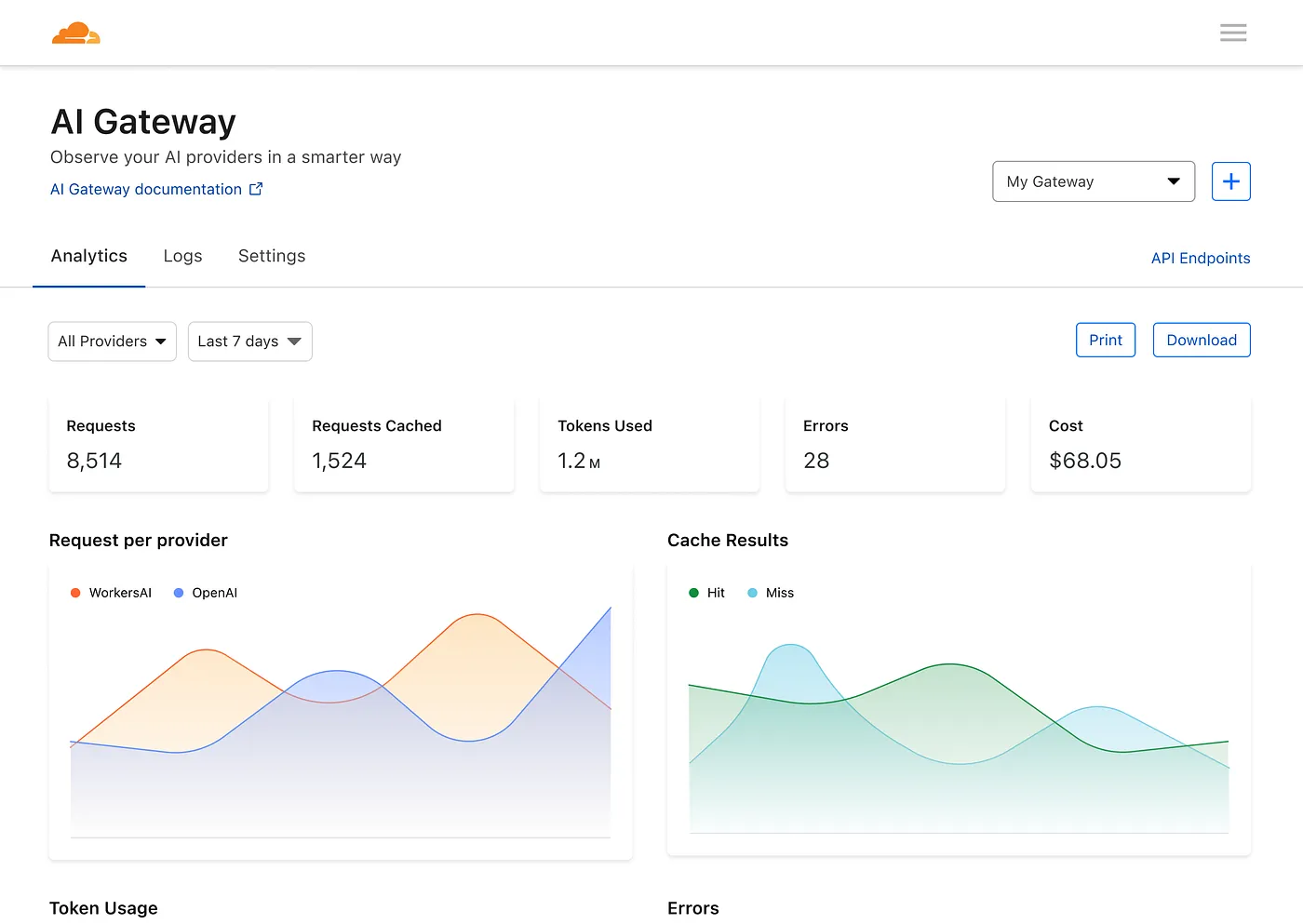
Então você tem um painel para ver métricas sobre solicitações, tokens, cache, erros e custo.
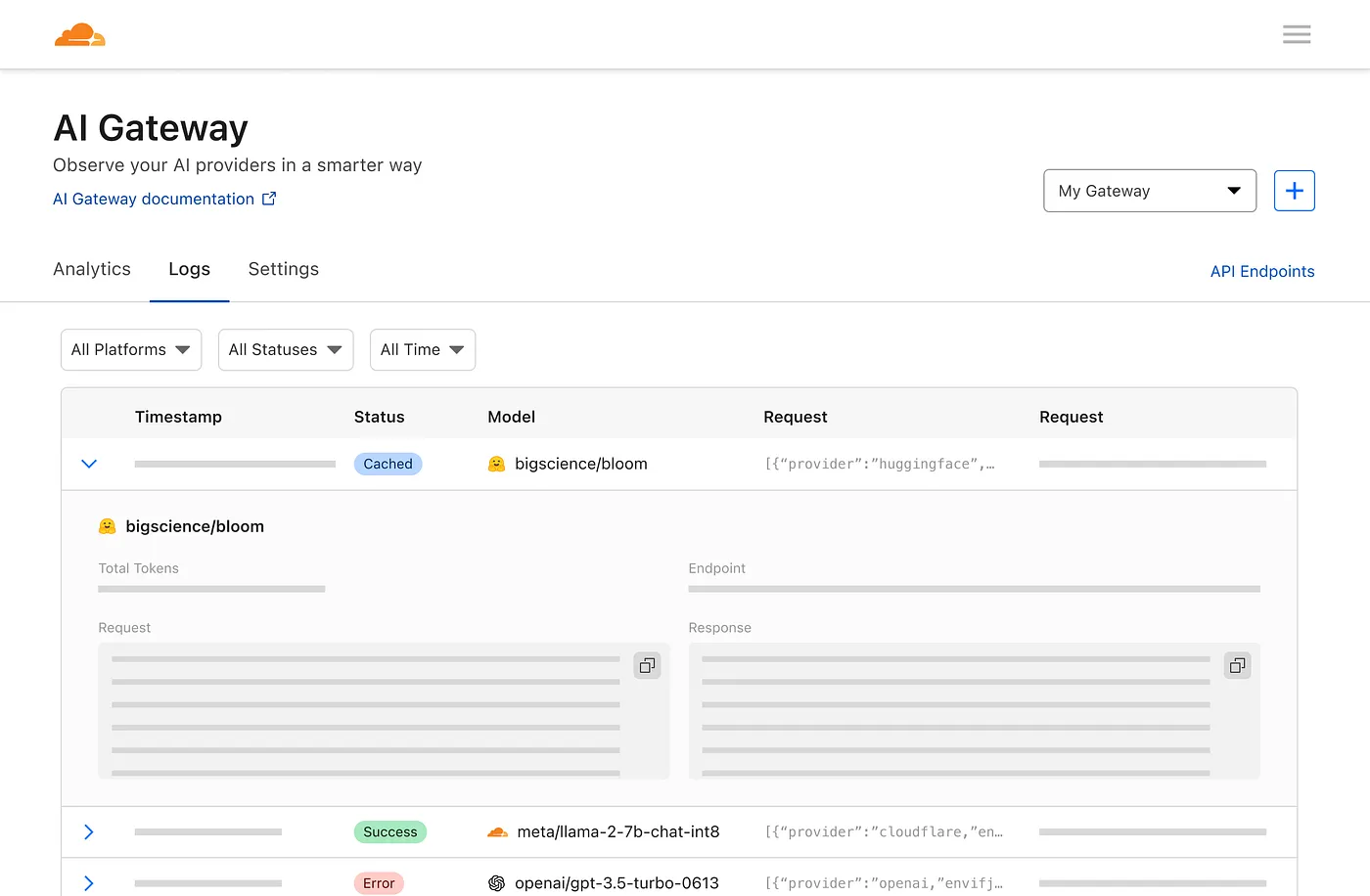
E uma página de registro para ver solicitações individuais, como o prompt, resposta, provedor, carimbos de data e hora e se a solicitação foi bem-sucedida, armazenada em cache ou se houve um erro.
Isso é fantástico, não é?
Costomização de Voz do Papel
Você pode personalizar a voz da função alterando o campo voice_name no arquivo de configuração da função.
{
"1": {
"tts_type": "openai-tts",
"tts_config": {
"voice_name": "alloy"
}
}
}
Encontre a voz que você gosta na OpenAI TTS Voice List.
Edge tts tem muitas vozes para escolher, aproveite assim:
{
"1": {
"tts_type": "edge-tts",
"tts_config": {
"voice_name": "en-NG-EzinneNeural"
}
}
}
Suporte à base de conhecimento
Para níveis mais altos de personalização, como suporte à base de conhecimento. Recomenda-se o uso do Dify, que combina os conceitos de Backend como Serviço e LLMOps, cobrindo a principal pilha de tecnologia necessária para criar aplicativos nativos de IA generativa, incluindo um mecanismo RAG integrado. Com o Dify, você pode implantar recursos como API de Assistentes e GPTs com base em qualquer modelo.
Vamos nos concentrar no mecanismo RAG integrado, que é um modelo gerativo baseado em recuperação que pode ser usado para tarefas como perguntas e respostas, diálogo e resumo de documentos. O Dify inclui vários recursos RAG baseados em indexação de texto completo ou incorporação de banco de dados vetorial, permitindo o upload direto de vários formatos de texto, como PDF e TXT. Carregue sua base de conhecimento, para que você não precise se preocupar com o brinquedo fazendo bobagens porque você não conhece o conhecimento de fundo.
O Dify pode ser implantado sozinho ou usar a versão em nuvem diretamente. A configuração no Folo também é muito simples:
{
"1": {
"llm_type": "dify",
"llm_config": {
"api_base": "http://192.168.52.164/v1",
"key": "app-AAAAAAAAAAAAAAAAAAa"
}
}
}
Forma de brinquedo personalizada
Em termos de princípio de funcionamento, qualquer brinquedo pode ser modificado. A Folo Toy também oferece o Octopus AI Development Kit, que pode transformar qualquer brinquedo comum em um brinquedo falante inteligente. O chip é pequeno e leve e pode caber facilmente em qualquer tipo de brinquedo, seja de pelúcia, plástico ou madeira.

Eu fiz um cacto que fala de Shaanxi. Use sua imaginação, você pode colocá-la em seus brinquedos favoritos, e não é particularmente complicado fazê-lo:
- abra o brinquedo
- Coloque o kit de desenvolvimento Octopus AI nele
- feche o brinquedo
O servidor ainda usa o mesmo. Você pode atribuir diferentes funções a diferentes brinquedos através do sn, que não será expandido aqui. Você pode verificar o documento de configuração no site oficial.
Notas de Segurança
Observe que nunca coloque a chave em um local público, como o GitHub, ou ela será abusada. Se sua chave vazar, exclua-a imediatamente na plataforma OpenAI e gere uma nova.
Você também pode usar variáveis de ambiente em docker-compose.yml e passá-las ao iniciar o contêiner, para evitar a exposição da chave no código.
services:
folotoy:
environment:
- OPENAI_OPENAI_KEY=${OPENAI_OPENAI_KEY}
OPENAI_OPENAI_KEY=sk-...i7TL docker compose up -d
Caso você deseje disponibilizar publicamente o FoloToy Server na Internet, é altamente recomendável proteger o serviço EMQX e permitir o acesso ao EMQX apenas com uma senha. Saiba mais sobre EMQX Security.
Conclusão
Criar seu próprio brinquedo LLM é uma jornada emocionante para o mundo da IA e da tecnologia. Se você é um entusiasta de bricolage ou um iniciante, este guia fornece o roteiro para criar algo verdadeiramente interativo e personalizado. Se você encontrar desafios para adquirir o Folotoy Core ou enfrentar quaisquer problemas ao longo do caminho, juntar-se ao nosso grupo Telegram oferece suporte da comunidade e aconselhamento especializado.

Para aqueles que preferem uma solução pronta, o produto acabado está disponível para compra aqui. Esta opção oferece a mesma experiência interativa sem a necessidade de montagem. Os brinquedos Folo também oferecem muitos outros produtos que podem ser encontrados aqui. Este é o endereço da loja deles: https://folotoy.taobao.com/
Compre produtos Folo Toy agora e aproveite os descontos fornecendo meu código promocional, F-001–9, ao entrar em contato com o atendimento ao cliente. Você pode economizar 20 RMB no Fofo G6, 15 RMB no Octopus Dev Suit e 10 RMB no Cactus. A maioria dos outros itens também se qualifica para um desconto de 10 RMB, mas entre em contato com o atendimento ao cliente para perguntar.




Embarque neste empreendimento criativo para dar vida ao seu companheiro de IA, aproveitando o vasto potencial dos brinquedos LLM para educação, entretenimento e muito mais.
Links de referência: