Guide le plus simple pour bricoler votre propre jouet LLM en 2024

2024 est là, et les jouets DIY LLM ? C'est totalement une chose maintenant. Aucune magie technologique n’est nécessaire, juste votre curiosité. J'ai franchi le pas, mélangeant un peu de codage avec beaucoup de plaisir, et bam, j'ai créé mon propre jouet parlant. Si vous êtes prêt à créer facilement un copain IA, vous êtes au bon endroit. Démystifions ensemble la technologie et donnons vie à votre ami IA. Dans un monde où la technologie recoupe de plus en plus la vie quotidienne, créer votre propre jouet LLM démystifie non seulement l’IA, mais offre également une passerelle personnalisée vers les merveilles de la technologie interactive.
Jetons d'abord un coup d'œil à l'effet final.
Honnêtement, c'est plutôt génial. Prêt à commencer? Allons-y !
Comment ça marche?
Il y a trois étapes clés :
- Enregistrement : recevez les données d'enregistrement en temps réel envoyées par le jouet via UDP et appelez l'API STT (Sound-To-Text) pour convertir le son en texte.
- Réflexion : Après avoir reçu le texte précédent, l'API LLM (Large-Language-Model) sera immédiatement appelée pour obtenir les phrases générées par le LLM de manière streaming. Ensuite, l'API TTS (Text-To-Sound) est appelée pour convertir les phrases en parole humaine.
- Lire l'audio : les jouets recevront les flux de fichiers audio TTS (Text-To-Sound) générés par le serveur FoloToy et les liront selon l'ordre.
Préparation avant le développement
Avant de commencer à fabriquer votre jouet LLM, il est crucial de comprendre le matériel, les logiciels et les connaissances techniques nécessaires. Cette section vous guidera dans la préparation de tous les éléments essentiels pour assurer un démarrage en douceur.
Matériel

Folotoy Core: La carte principale de conversation vocale ChatGPT AI sert de cerveau à votre projet, permettant des interactions vocales avec l'IA.

Composants du jouet : des éléments essentiels comme un microphone, un haut-parleur, des boutons, des interrupteurs et une alimentation électrique sont nécessaires. J'utilise le Alilo Honey Bunny G6 pour sa configuration prête à l'emploi.

Octopus Dev Suit (Autre choix) : Idéal pour ceux qui cherchent à moderniser les jouets existants avec des capacités d'IA.
Lors d'un achat, fournissez mon code promotionnel F-001–9 pour bénéficier d'une réduction.
Serveur
Utiliser votre propre machine, comme un MacBook Pro, pour garantir que votre jouet dispose d'un backend fiable pour traiter et répondre aux interactions vocales. Alternativement, les services cloud tels que Google Cloud Engine (GCE) peuvent faire évoluer votre projet vers des applications plus larges.
Connaissance
- Docker (obligatoire) : Comprendre Docker est crucial pour déployer des logiciels dans des conteneurs, rendant ainsi votre projet portable et évolutif. Je l'utilise pour démarrer le serveur Folo.
- Git (obligatoire) : le contrôle de version est essentiel pour gérer la base de code de votre projet. Je l'utilise pour gérer la base de code du serveur Folo.
- MQTT (facultatif) : Si vous souhaitez une personnalisation avancée, la connaissance de MQTT (un protocole de messagerie léger) sera bénéfique pour la communication entre le jouet et le serveur.
- EMQX (facultatif) : courtier MQTT open source pour l'IoT, l'IIoT et les véhicules connectés. Utilisé pour gérer vos jouets.
- ollama (facultatif) : si vous souhaitez exécuter de grands modèles de langage localement, c'est un bon choix.
Services et inscription
Pour donner vie à votre jouet, vous aurez besoin d'accéder à des services d'IA spécifiques. Pour ce projet, j'ai choisi d'utiliser les offres d'OpenAI :
- TTS (Text-to-Speech) : le service Whisper d'OpenAI convertit les réponses textuelles de l'IA en parole, rendant l'interaction naturelle.
- LLM (Large Language Model) : utilisation des modèles d'OpenAI pour comprendre et générer des réponses textuelles de type humain.
- STT (Speech-to-Text) : le service TTS d'OpenAI transcrit les mots prononcés en texte, permettant à l'IA de comprendre les commandes vocales ou les requêtes.
Le plus important est que vous devez vous inscrire sur la plateforme OpenAI et créer une clé, comme sk-...i7TL.
Assemblez votre jouet
Il est maintenant temps de rassembler toutes les pièces et de créer votre propre jouet LLM.
Les étapes générales sont les suivantes, il est recommandé de regarder d'abord le tutoriel vidéo.
- Vérifiez si l'enregistrement et la lecture de l'Alilo G6 sont normaux.
- Utilisez un tournevis pour dévisser les 6 vis à l'arrière de l'Alilo G6.
- Ouvrez soigneusement le boîtier de l'Alilo G6, débranchez toutes les fiches de la carte mère, débranchez d'abord la fiche d'alimentation, il y a de la colle sur la fiche, vous pouvez utiliser un couteau d'art pour l'ouvrir doucement, assurez-vous de ne pas vous couper la main.
- Dévissez les 4 vis de la carte mère et retirez-la.
- Remplacez la carte mère d'origine par la carte mère FoloToy et serrez 3 vis pour la fixer.
- Branchez le microphone, la lumière, le haut-parleur et les prises de courant, branchez enfin la prise de courant.
- Après avoir branché toutes les prises, ne fermez pas encore le boîtier et n'installez pas de vis. Allumez d'abord l'interrupteur marche/arrêt sur la queue du lapin pour voir si la lumière nouvellement installée peut s'allumer et clignoter lentement en bleu.
- S'il n'y a aucun problème, installez le boîtier et serrez les vis pour terminer le processus de remplacement.
Configurer le serveur
Une prise en charge backend solide est essentielle pour que vos jouets LLM comprennent et répondent aux commandes vocales. Cette section vous apprendra comment cloner la base de code du serveur, configurer le serveur et démarrer les conteneurs Docker pour garantir que vos jouets disposent d'un support backend stable. Clonez d’abord la base de code du serveur Folo depuis GitHub.
git clone [email protected]:FoloToy/folotoy-server-self-hosting.git
Modifiez ensuite la configuration du serveur de base dans le fichier docker-compose.yml par la vôtre.
| Nom | Descriptif | Exemple |
|---|---|---|
| OPENAI_OPENAI_KEY | Votre clé API OpenAI. | sk-...i7TL |
| OPENAI_TTS_KEY | Votre clé API OpenAI. | sk-...i7TL |
| OPENAI_WHISPER_KEY | Votre clé API OpenAI. | sk-...i7TL |
| AUDIO_DOWNLOAD_URL | L'URL du fichier audio. | http://192.168.xx:8082 |
| SPEECH_UDP_SERVER_HOST | L'adresse IP de votre serveur. | 192.168.xx |
Configurez ensuite vos rôles dans le fichier config/roles.json, voici un exemple minimal, pour une configuration complète, veuillez vous référer à la documentation Folotoy.
{
"1": {
"start_text": "Bonjour, que puis-je faire pour vous ?",
"prompt": "You are a helpful assistant."
}
}
Démarrez ensuite les conteneurs Docker.
docker compose up -d
J'exécute le serveur Folo sur ma propre machine, si vous souhaitez l'exécuter dans le cloud, c'est presque la même chose. Une chose à noter est que vous devez exposer les ports 1883, 8082, 8085, 18083 et 8083 au réseau public. Pour plus d'informations, veuillez vous référer à la documentation Folotoy.
Discutez avec votre jouet
Une fois que tout est prêt, il est temps d'interagir avec votre jouet LLM. Allumez l'interrupteur à l'arrière du jouet pour l'allumer. La lumière bleue clignotante dans les oreilles indique que le jouet est entré en mode d'appairage.
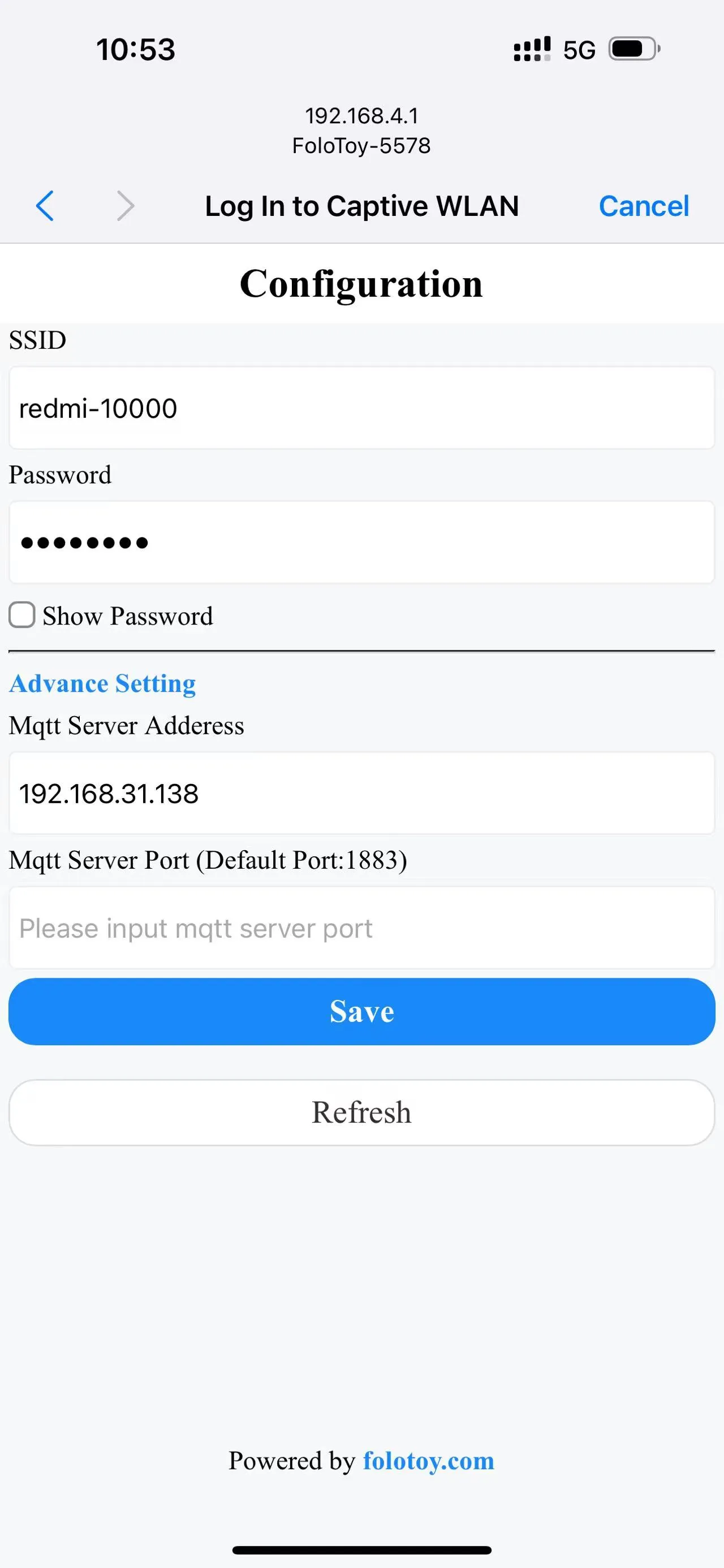
Allumez votre téléphone ou votre ordinateur et sélectionnez le réseau sans fil « FoloToy-xxxx ». Après un moment, votre téléphone ou votre ordinateur ouvrira automatiquement une page de configuration où vous pourrez définir le réseau WiFi (SSID et mot de passe) auquel vous connecter, ainsi que l'adresse du serveur (comme 192.168.xx) et le numéro de port (conserver la valeur par défaut 1883).

Une fois le réseau configuré et connecté au serveur, appuyez sur le gros bouton rond au milieu pour démarrer la conversation. Après avoir arrêté de parler, FoloToy émettra un bip pour indiquer la fin de l'enregistrement. Les 7 petits boutons ronds autour sont des boutons de changement de rôle. Après avoir cliqué, le changement de rôle prend effet.
Débogage
Qu'il s'agisse d'un serveur ou d'un jouet, vous pourrez rencontrer quelques problèmes techniques. Cette section fournira quelques conseils et outils de débogage de base pour vous aider à diagnostiquer et à résoudre d'éventuels problèmes et à garantir le bon fonctionnement de vos jouets LLM.
Débogage du serveur
Pour vérifier les journaux du serveur, exécutez la commande suivante.
docker compose logs -f
LOG_LEVEL peut être défini dans le fichier docker-compose.yml pour contrôler le niveau de journalisation.
Débogage des jouets
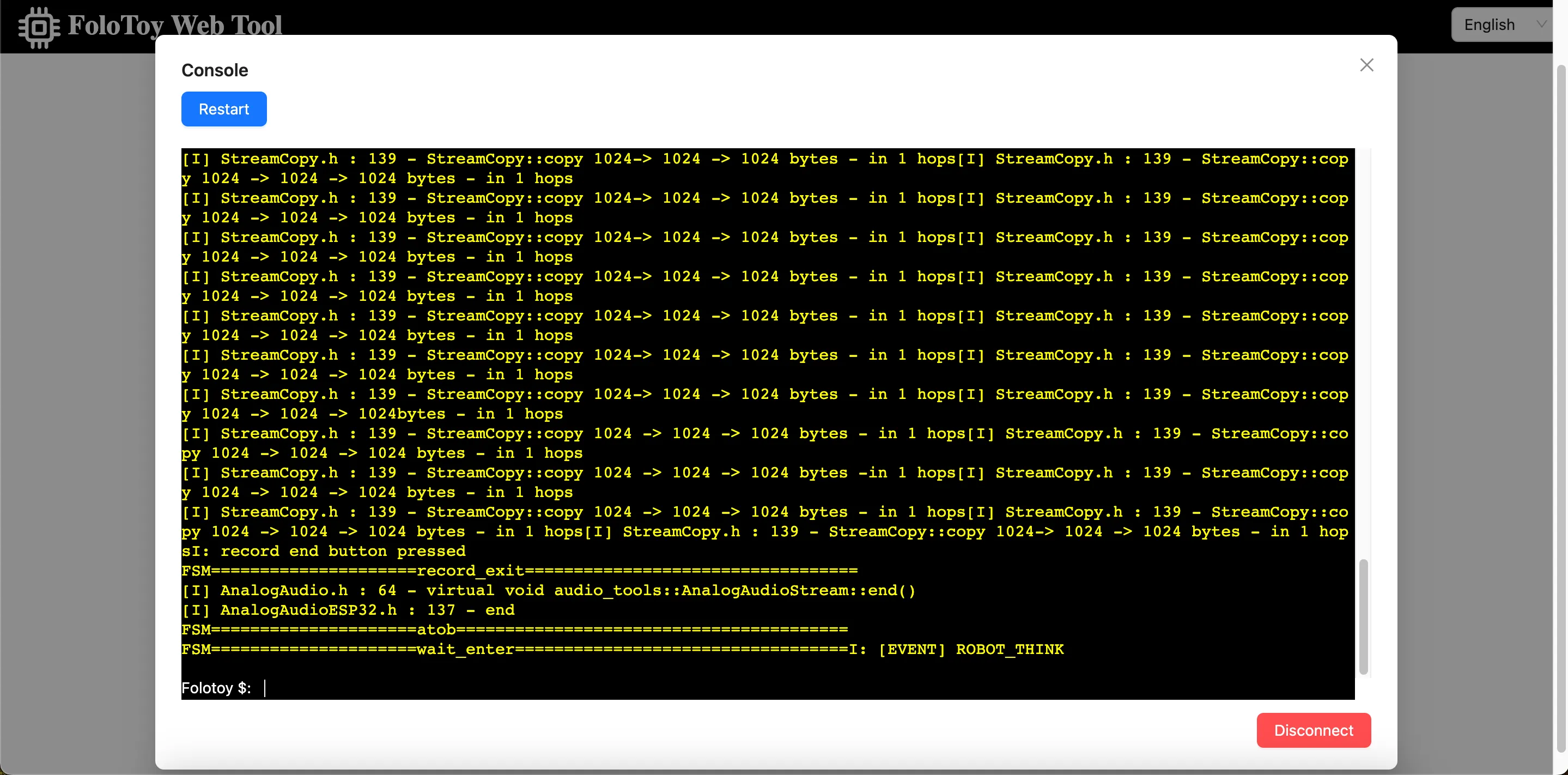
Folo Toy fournit un moyen simple de déboguer la base du jouet sur le port série USB. Vous pouvez utiliser le Folo Toy Web Tool pour déboguer le jouet.
- Connectez le jouet à votre ordinateur à l'aide d'un câble USB.
- Ouvrez l'outil Web Folo Toy, puis cliquez sur le bouton « Console » pour vous connecter au jouet.
- Une fois connecté, vous devriez pouvoir voir les journaux en temps réel de votre appareil dans la console.
Il y a également une LED sur le jouet, elle s'allumera de différentes couleurs pour indiquer l'état du jouet .
Débogage MQTT
Ouvrez le Tableau de bord EMQX pour vérifier les messages MQTT. Le nom d'utilisateur par défaut est admin et le mot de passe est public. Quoi qu'il en soit, remplacez le mot de passe par un mot de passe sécurisé après vous être connecté.
Personnalisation avancée
Pour les utilisateurs avancés qui souhaitent explorer et personnaliser davantage leurs jouets LLM, cette section expliquera comment exécuter localement de grands modèles de langage, utiliser des outils tels que CloudFlare AI Gateway et personnaliser la voix des personnages. Cela vous ouvrira un monde plus large de jouets DIY LLM.
Exécuter le LLM localement

Exécuter localement de grands modèles de langage est une chose intéressante. Vous pouvez exécuter Llama 2, Gemma et toutes sortes de grands modèles open source du monde entier, même des modèles formés par vous-même. En utilisant ollama, vous pouvez le faire facilement. Installez d'abord ollama, puis exécutez la commande suivante pour exécuter le modèle Llama 2.
ollama run llama2
Ensuite, modifiez la configuration du rôle pour utiliser le modèle LLM local.
{
"1": {
"start_text": "Bonjour, que puis-je faire pour vous?",
"prompt": "You are a helpful assistant.",
"llm_type": "ollama",
"llm_config": {
"api_base": "http://host.docker.internal:11434",
"model": "llama2"
}
}
}
L'api_base doit être l'adresse de votre serveur ollama, et n'oubliez pas de redémarrer le serveur Folo pour que les modifications prennent effet.
docker compose restart folotoy
C'est tout, changez de modèle pour Gemma ou d'autres modèles à votre guise et profitez-en.
Utiliser CloudFlare AI Gateway
AI Gateway de Cloudflare vous permet de gagner en visibilité et en contrôle sur vos applications d'IA. En connectant vos applications à AI Gateway, vous pouvez recueillir des informations sur la manière dont les utilisateurs utilisent votre application grâce à l'analyse et à la journalisation, puis contrôler la manière dont votre application évolue grâce à des fonctionnalités telles que la mise en cache, la limitation du débit, ainsi que les nouvelles tentatives de requête, le repli du modèle, etc. .
Tout d'abord, vous devez créer une nouvelle AI Gateway.
Modifiez ensuite le fichier docker-compose.yml pour remplacer OPENAI_OPENAI_API_BASE par l'adresse de votre AI Gateway, comme ceci :
services:
folotoy:
environment: OPENAI_OPENAI_API_BASE=https://gateway.ai.cloudflare.com/v1/${ACCOUNT_TAG}/${GATEWAY}/openai
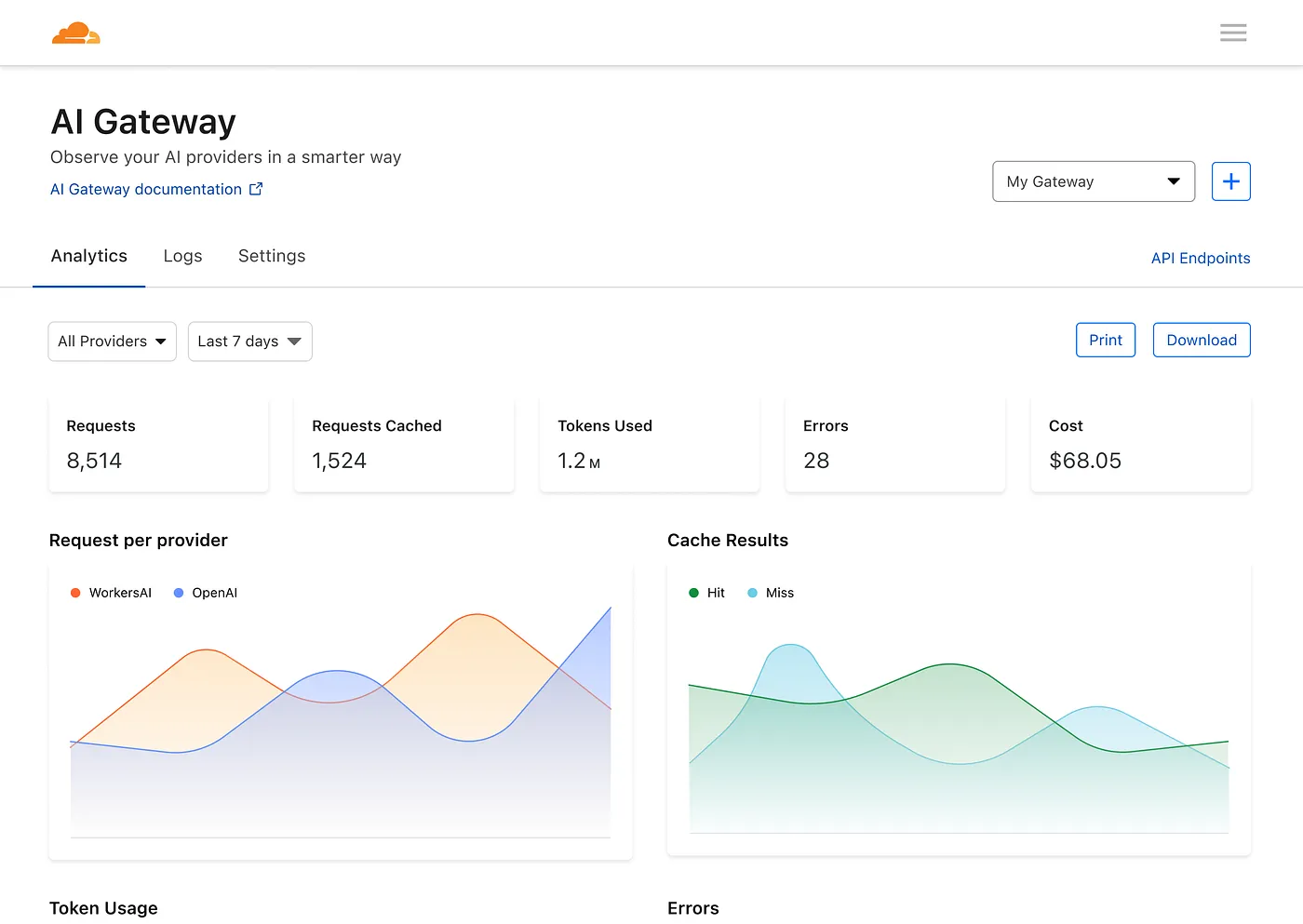
Vous disposez ensuite d'un tableau de bord pour afficher les métriques sur les requêtes, les jetons, la mise en cache, les erreurs et les coûts.
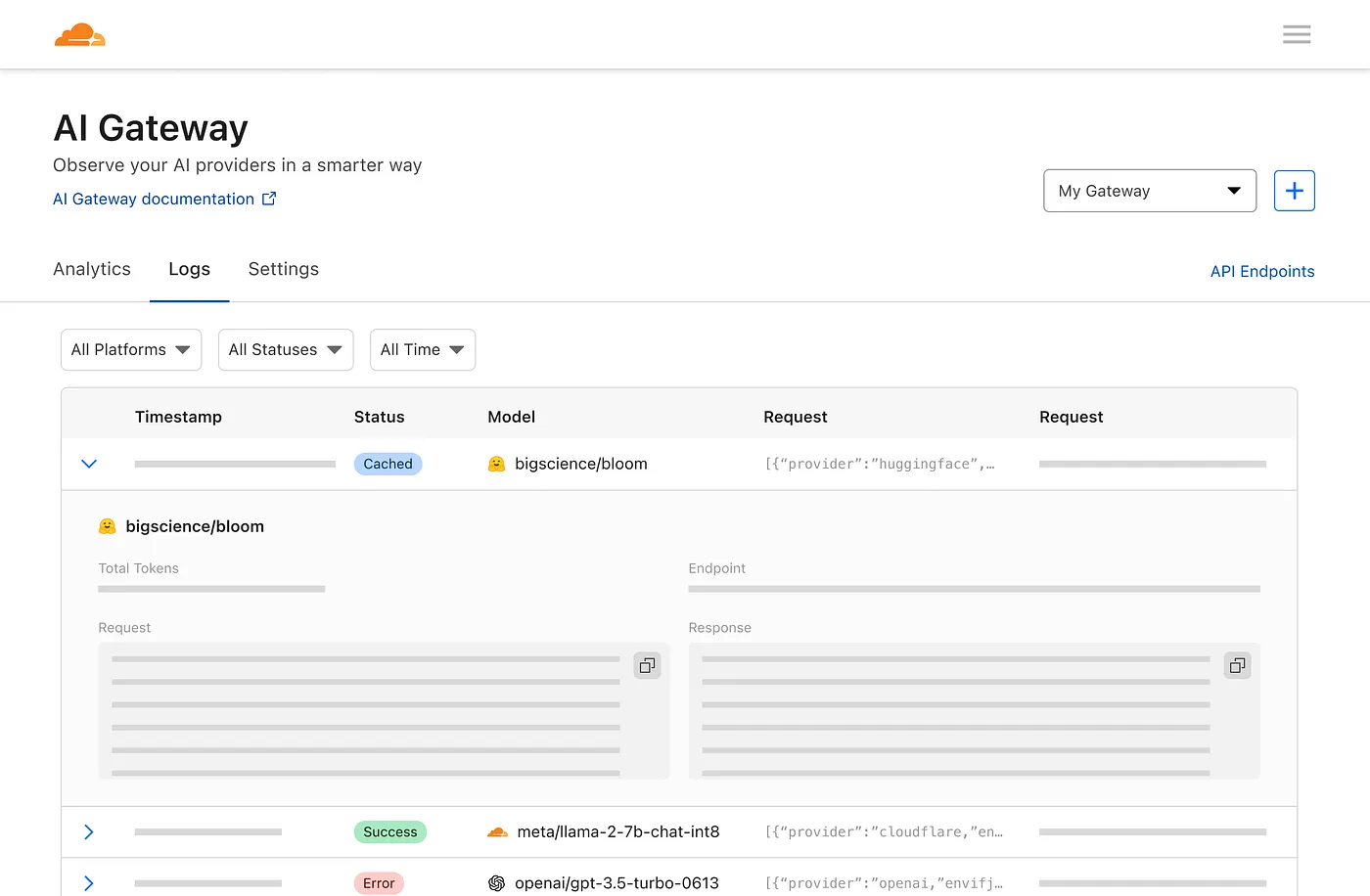
Et une page de journalisation pour voir les demandes individuelles, telles que l'invite, la réponse, le fournisseur, les horodatages et si la demande a réussi, mise en cache ou s'il y a eu une erreur.
C'est fantastique, n'est-ce pas ?
Personnalisation de la voix des rôles
Vous pouvez personnaliser la voix du rôle en modifiant le champ voice_name dans le fichier de configuration du rôle.
{
"1": {
"tts_type": "openai-tts",
"tts_config": {
"voice_name": "alloy"
}
}
}
Trouvez la voix que vous aimez dans la Liste des voix OpenAI TTS.
Edge tts propose de nombreuses voix, profitez-en comme ceci :
{
"1": {
"tts_type": "edge-tts",
"tts_config": {
"voice_name": "en-NG-EzinneNeural"
}
}
}
Prise en charge de la base de connaissances
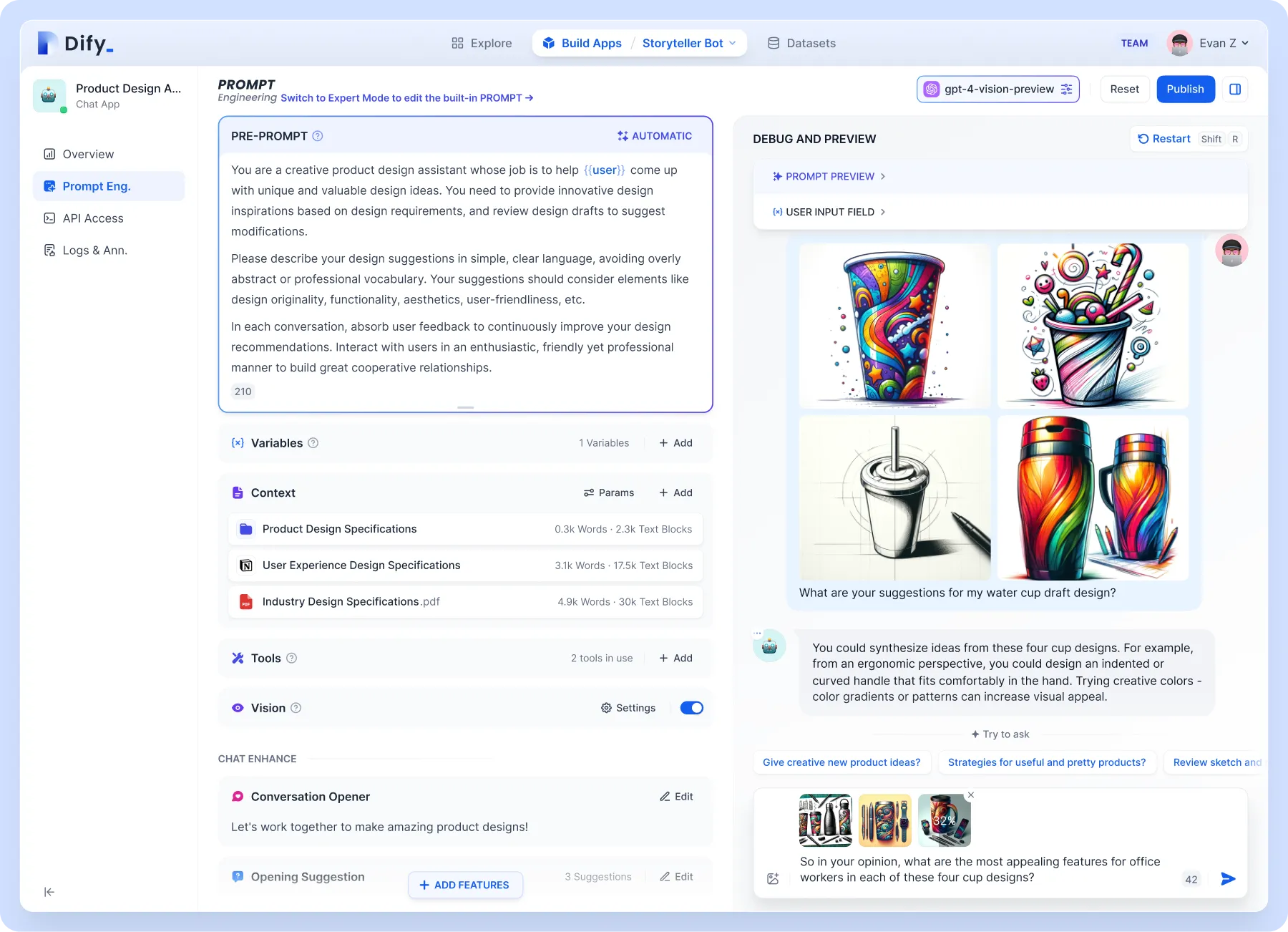
Pour des niveaux de personnalisation plus élevés, tels que la prise en charge de la base de connaissances. Il est recommandé d'utiliser Dify, qui combine les concepts de Backend as Service et de LLMOps, couvrant la pile technologique de base requise pour créer des applications natives d'IA générative, y compris un moteur RAG intégré. Avec Dify, vous pouvez auto-déployer des fonctionnalités telles que l'API Assistants et les GPT basées sur n'importe quel modèle.
Concentrons-nous sur le moteur RAG intégré, qui est un modèle génératif basé sur la récupération qui peut être utilisé pour des tâches telles que les questions et réponses, le dialogue et la synthèse de documents. Dify inclut diverses fonctionnalités RAG basées sur l'indexation de texte intégral ou l'intégration de bases de données vectorielles, permettant le téléchargement direct de divers formats de texte tels que PDF et TXT. Téléchargez votre base de connaissances afin que vous n'ayez pas �à vous soucier des bêtises du jouet parce que vous ne connaissez pas les connaissances de base.
Dify peut être déployé seul ou utiliser directement la version cloud. La configuration sur Folo est également très simple :
{
"1": {
"llm_type": "dify",
"llm_config": {
"api_base": "http://192.168.52.164/v1",
"key": "app-AAAAAAAAAAAAAAAAAAa"
}
}
}
Forme de jouet personnalisée
En termes de principe de fonctionnement, n'importe quel jouet peut être modifié. Folo Toy propose également le kit de développement Octopus AI, qui peut transformer n'importe quel jouet ordinaire en un jouet parlant intelligent. La puce est petite et légère et peut facilement s'insérer dans tout type de jouet, qu'il soit en peluche, en plastique ou en bois.

J'ai bricolé un cactus parlant le Shaanxi. Utilisez votre imagination, vous pouvez la mettre dans vos jouets préférés, et ce n'est pas particulièrement compliqué à faire :
- ouvrez le jouet
- Mettez-y le kit de développement Octopus AI
- fermez le jouet
Le serveur utilise toujours le même. Vous pouvez attribuer différents rôles à différents jouets via sn, qui ne sera pas développé ici. Vous pouvez consulter le document de configuration sur le site officiel.
Notes de sécurité
Attention, ne mettez jamais la clé dans un lieu public, tel que GitHub, sinon elle sera utilisée de manière abusive. Si votre clé est divulguée, supprimez-la immédiatement sur la plateforme OpenAI et générez-en une nouvelle.
Vous pouvez également utiliser des variables d'environnement dans docker-compose.yml et les transmettre lors du démarrage du conteneur, afin d'éviter d'exposer la clé dans le code.
services:
folotoy:
environment:
- OPENAI_OPENAI_KEY=${OPENAI_OPENAI_KEY}
OPENAI_OPENAI_KEY=sk-...i7TL docker compose up -d
Dans le cas où vous souhaitez rendre FoloToy Server accessible au public sur Internet, il est fortement recommandé de sécuriser le service EMQX et d'autoriser l'accès à EMQX uniquement avec un mot de passe. En savoir plus sur EMQX Security.
Conclusion
Fabriquer votre propre jouet LLM est un voyage passionnant dans le monde de l'IA et de la technologie. Que vous soyez un bricoleur ou un débutant, ce guide fournit la feuille de route pour créer quelque chose de vraiment interactif et personnalisé. Si vous rencontrez des difficultés pour acquérir le Folotoy Core ou rencontrez des problèmes en cours de route, rejoindre notre groupe Telegram offre un soutien communautaire et des conseils d'experts.

Pour ceux qui préfèrent une solution toute faite, le produit fini est disponible à l'achat ici. Cette option offre la même expérience interactive sans avoir besoin d’assemblage. Les jouets Folo proposent également de nombreux autres produits que vous pouvez trouver ici. Voici l'adresse de leur magasin : https://folotoy.taobao.com/
Achetez les produits Folo Toy maintenant et profitez de réductions en fournissant mon code promotionnel, F-001-9, lorsque vous contactez le service client. Vous pouvez économiser 20 RMB sur le Fofo G6, 15 RMB sur l'Octopus Dev Suit et 10 RMB sur le Cactus. La plupart des autres articles bénéficient également d'une réduction de 10 RMB, mais veuillez contacter le service client pour vous renseigner.




Lancez-vous dans cette aventure créative pour donner vie à votre compagnon IA, en exploitant le vaste potentiel des jouets LLM pour l'éducation, le divertissement et au-delà.
Liens de référence :