Der einfachste Leitfaden zum Selbermachen Ihres eigenen LLM-Spielzeugs im Jahr 2024

Das Jahr 2024 ist da und DIY-LLM-Spielzeug? Absolut eine Sache jetzt. Es ist keine technische Zauberei erforderlich, nur Ihre Neugier. Ich habe den Sprung gewagt, ein bisschen Programmieren mit einer Menge Spaß kombiniert und bam – mein eigenes sprechendes Spielzeug entwickelt. Wenn Sie Lust haben, mit Leichtigkeit einen KI-Kumpel zu erschaffen, sind Sie hier genau richtig. Lassen Sie uns gemeinsam die Technik entmystifizieren und Ihren KI-Freund zum Leben erwecken. In einer Welt, in der sich Technologie zunehmend mit dem täglichen Leben überschneidet, entmystifiziert die Entwicklung eines eigenen LLM-Spielzeugs nicht nur die KI, sondern bietet auch einen personalisierten Zugang zu den Wundern der interaktiven Technologie.
Schauen wir uns zunächst den endgültigen Effekt an.
Ehrlich gesagt ist es ziemlich großartig. Bereit zum Start? Lass uns eintauchen!
Wie funktioniert es?
Es gibt drei wichtige Schritte:
- Aufnahme: Empfangen Sie die vom Spielzeug gesendeten Echtzeit-Aufnahmedaten über UDP und rufen Sie die STT-API (Sound-To-Text) auf, um den Ton in Text umzuwandeln.
- Denken: Nach Erhalt des vorherigen Textes wird sofort die LLM-API (Large-Language-Model) aufgerufen, um vom LLM generierte Sätze auf Streaming-Weise abzurufen. Anschließend wird die TTS-API (Text-To-Sound) aufgerufen, um die Sätze in menschliche Sprache umzuwandeln.
- Audio abspielen: Toys empfängt vom FoloToy-Server generierte TTS-Audiodateistreams (Text-To-Sound) und spielt sie entsprechend der Reihenfolge ab.
Vorbereitung vor der Entwicklung
Bevor Sie mit der Herstellung Ihres LLM-Spielzeugs beginnen, ist es wichtig, die erforderliche Hardware, Software und das technische Wissen zu kennen. In diesem Abschnitt erfahren Sie, wie Sie alles Notwendige vorbereiten, um einen reibungslosen Start zu gewährleisten.
Hardware

Folotoy Core: Das ChatGPT AI Voice Conversation Core Board dient als Gehirn Ihres Projekts und ermöglicht Sprachinteraktionen mit KI.

Spielzeugkomponenten: Wesentliche Dinge wie ein Mikrofon, ein Lautsprecher, Tasten, Schalter und ein Netzteil sind erforderlich. Ich wähle den Alilo Honey Bunny G6 wegen seiner gebrauchsfertigen Einrichtung.

Octopus Dev Suit (Andere Auswahl): Ideal für alle, die bestehende Spielzeuge mit KI-Fähigkeiten nachrüsten möchten.
Geben Sie beim Kauf meinen Aktionscode F-001–9 an, um einen Rabatt zu erhalten.
Server
Nutzen Sie Ihre eigene Maschine, wie zum Beispiel ein MacBook Pro, um sicherzustellen, dass Ihr Spielzeug über ein zuverlässiges Backend verfügt, um Sprachinteraktionen zu verarbeiten und darauf zu reagieren. Alternativ können Cloud-Dienste wie Google Cloud Engine (GCE) Ihr Projekt für breitere Anwendungen skalieren.
Wissen
- Docker (erforderlich): Kenntnisse über Docker sind entscheidend für die Bereitstellung von Software in Containern, damit Ihr Projekt portierbar und skalierbar wird. Ich verwende es zum Starten des Folo-Servers.
- Git (erforderlich): Die Versionskontrolle ist für die Verwaltung der Codebasis Ihres Projekts unerlässlich. Ich verwende es zum Verwalten der Folo-Server-Codebasis.
- MQTT (optional): Wenn Sie eine erweiterte Anpassung anstreben, ist die Vertrautheit mit MQTT (einem einfachen Nachrichtenprotokoll) für die Kommunikation zwischen dem Spielzeug und dem Server von Vorteil.
- EMQX (optional): Open-Source-MQTT-Broker für IoT, IIoT und vernetzte Fahrzeuge. Wird zur Verwaltung Ihres Spielzeugs verwendet.
- ollama (optional): Wenn Sie große Sprachmodelle lokal ausführen möchten, ist dies eine gute Wahl.
Dienste und Registrierung
Um Ihr Spielzeug zum Leben zu erwecken, benötigen Sie Zugriff auf bestimmte KI-Dienste. Für dieses Projekt habe ich mich für die Nutzung der Angebote von OpenAI entschieden:
- TTS (Text-to-Speech): Der Whisper-Dienst von OpenAI wandelt Textantworten der KI in Sprache um und sorgt so für eine natürliche Interaktion.
- LLM (Large Language Model): Nutzung der OpenAI-Modelle zum Verstehen und Generieren menschenähnlicher Textantworten.
- STT (Speech-to-Text): Der TTS-Dienst von OpenAI wandelt gesprochene Wörter in Text um, sodass die KI Sprachbefehle oder Abfragen verstehen kann.
Das Wichtigste ist, dass Sie sich auf der OpenAI-Plattform registrieren und einen Schlüssel erstellen müssen. wie sk-...i7TL.
Bauen Sie Ihr Spielzeug zusammen
Jetzt ist es an der Zeit, alle Teile zusammenzusetzen und Ihr eigenes LLM-Spielzeug herzustellen.
Die allgemeinen Schritte sind wie folgt. Es wird empfohlen, sich zuerst das Video-Tutorial anzusehen.
- Überprüfen Sie, ob Aufnahme und Wiedergabe des Alilo G6 normal sind.
- Lösen Sie mit einem Schraubendreher die 6 Schrauben auf der Rückseite des Alilo G6.
- Öffnen Sie vorsichtig das Gehäuse des Alilo G6, ziehen Sie alle Stecker auf dem Motherboard ab. Ziehen Sie zuerst den Netzstecker. Auf dem Stecker befindet sich Kleber. Sie können ihn mit einem Kunstmesser vorsichtig aufschneiden. Achten Sie darauf, sich nicht die Hand zu schneiden.
- Lösen Sie die 4 Schrauben am Motherboard und entfernen Sie es.
- Ersetzen Sie das Original-Motherboard durch das Motherboard von FoloToy und ziehen Sie 3 Schrauben fest, um es zu befestigen.
- Mikrofon, Licht, Lautsprecher und Steckdosen einstecken, abschließend Steckdose einstecken.
- Schließen Sie nach dem Einstecken aller Steckdosen das Gehäuse noch nicht und montieren Sie die Schrauben noch nicht. Schalten Sie zunächst den Ein-/Ausschalter am Kaninchenschwanz ein, um zu sehen, ob sich das neu installierte Licht einschalten und langsam blau blinken lässt.
- Wenn kein Problem vorliegt, installieren Sie das Gehäuse und ziehen Sie die Schrauben fest, um den Austauschvorgang abzuschließen.
Richten Sie den Server ein
Eine starke Backend-Unterstützung ist der Schlüssel dafür, dass Ihre LLM-Spielzeuge Sprachbefehle verstehen und darauf reagieren. In diesem Abschnitt erfahren Sie, wie Sie die Servercodebasis klonen, den Server konfigurieren und Docker-Container starten, um sicherzustellen, dass Ihre Spielzeuge über eine stabile Backend-Unterstützung verfügen. Klonen Sie zunächst die Folo-Server-Codebasis von GitHub.
git clone [email protected]:FoloToy/folotoy-server-self-hosting.git
Ändern Sie dann die Basisserverkonfiguration in der Datei docker-compose.yml in Ihre eigene.
| Name | Beschreibung | Beispiel |
|---|---|---|
| OPENAI_OPENAI_KEY | Ihr OpenAI-API-Schlüssel. | sk-...i7TL |
| OPENAI_TTS_KEY | Ihr OpenAI-API-Schlüssel. | sk-...i7TL |
| OPENAI_WHISPER_KEY | Ihr OpenAI-API-Schlüssel. | sk-...i7TL |
| AUDIO_DOWNLOAD_URL | Die URL der Audiodatei. | http://192.168.xx:8082 |
| SPEECH_UDP_SERVER_HOST | Die IP-Adresse Ihres Servers. | 192.168.xx |
Konfigurieren Sie dann Ihre Rollen in der Datei config/roles.json. Hier ist ein Minimalbeispiel. Die vollständige Konfiguration finden Sie in der Folotoy-Dokumentation.
{
"1": {
"start_text": "Hallo, was kann ich für Sie tun?",
"prompt": "You are a helpful assistant."
}
}
Anschließend starten Sie die Docker-Container.
docker compose up -d
Ich betreibe den Folo-Server auf meinem eigenen Computer. Wenn Sie ihn in der Cloud ausführen möchten, ist es fast dasselbe. Beachten Sie, dass Sie die Ports 1883, 8082, 8085, 18083 und 8083 dem öffentlichen Netzwerk zugänglich machen müssen.
Weitere Informationen finden Sie in der Folotoy-Dokumentation.
Chatte mit deinem Spielzeug
Sobald alles fertig ist, ist es Zeit, mit Ihrem LLM-Spielzeug zu interagieren. Schalten Sie den Schalter auf der Rückseite des Spielzeugs ein, um es einzuschalten. Das blau blinkende Licht in den Ohren zeigt an, dass das Spielzeug in den Kopplungsmodus gewechselt ist.
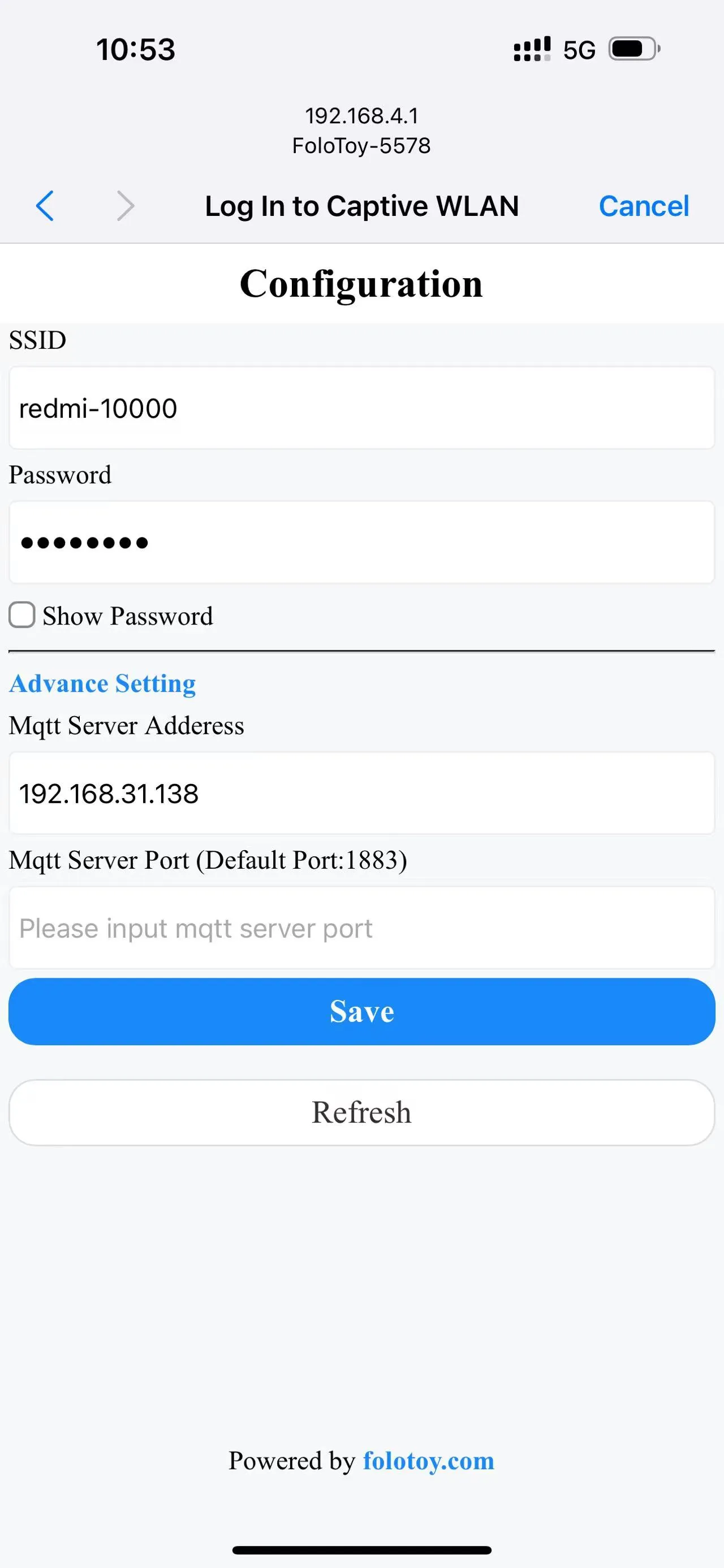
Schalten Sie Ihr Telefon oder Ihren Computer ein und wählen Sie das drahtlose Netzwerk „FoloToy-xxxx“ aus. Nach einem Moment öffnet Ihr Telefon oder Computer automatisch eine Konfigurationsseite, auf der Sie festlegen können, mit welchem WLAN-Netzwerk (SSID und Passwort) eine Verbindung hergestellt werden soll, sowie die Serveradresse (z. B. 192.168.xx) und die Portnummer (behalten Sie die Standardeinstellung 1883 bei).

Nachdem das Netzwerk konfiguriert und mit dem Server verbunden ist, drücken Sie die große runde Taste in der Mitte, um das Gespräch zu starten. Nachdem Sie aufgehört haben zu sprechen, gibt FoloToy einen Piepton aus, um das Ende der Aufnahme anzuzeigen.
Die 7 runden kleinen Knöpfe rundherum sind Rollenwechselknöpfe. Nach dem Klicken wird der Rollenwechsel wirksam.
Debuggen
Unabhängig davon, ob es sich um einen Server oder ein Spielzeug handelt, können technische Probleme auftreten. In diesem Abschnitt finden Sie einige grundlegende Debugging-Tipps und Tools, die Ihnen bei der Diagnose und Lösung möglicher Probleme helfen und sicherstellen, dass Ihre LLM-Spielzeuge reibungslos funktionieren.
Server-Debugging
Führen Sie den folgenden Befehl aus, um die Serverprotokolle zu überprüfen.
docker compose logs -f
LOG_LEVEL kann in der Datei docker-compose.yml festgelegt werden, um die Protokollebene zu steuern.
Spielzeug-Debugging
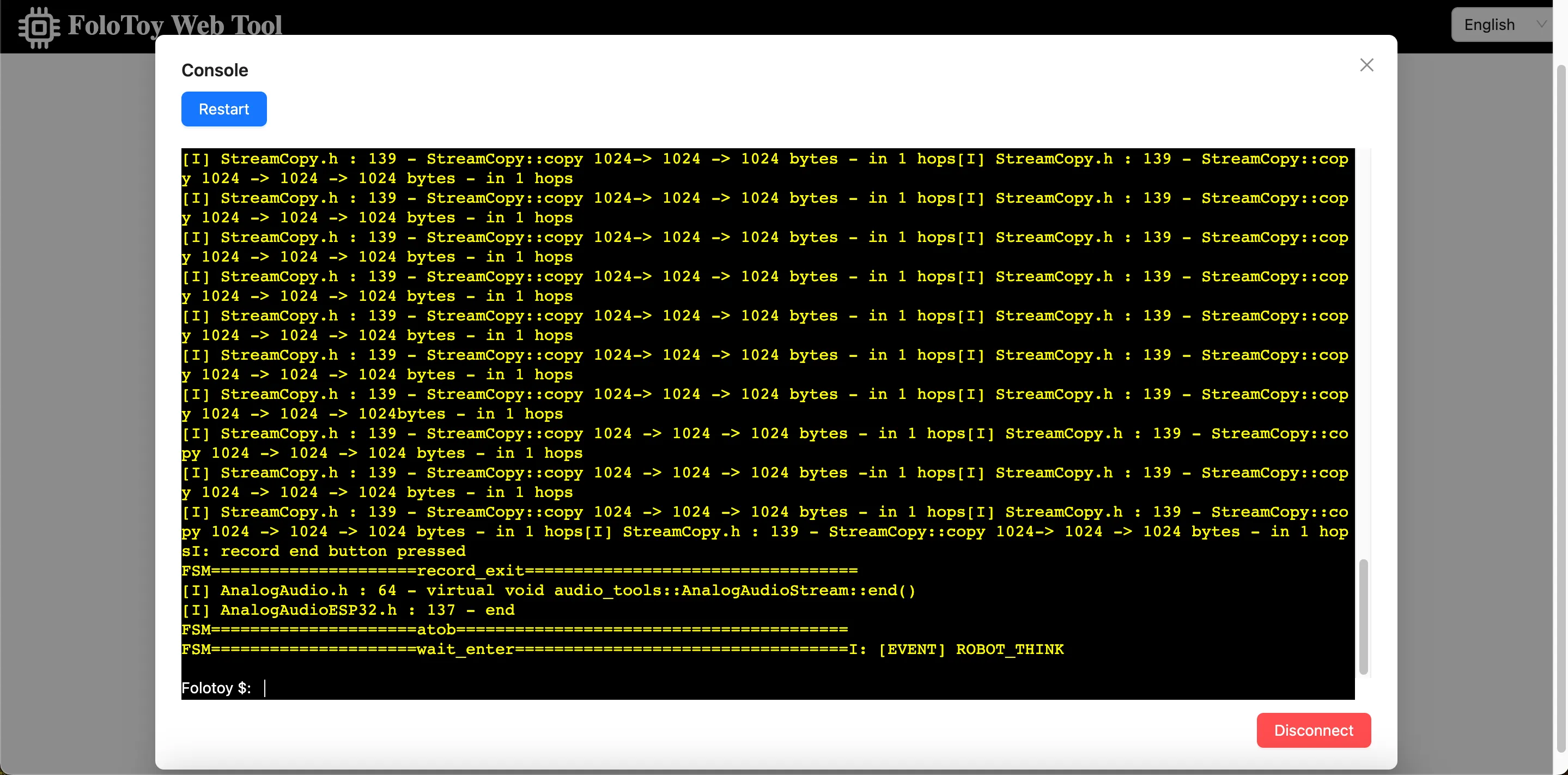
Folo Toy bietet eine einfache Möglichkeit, die Spielzeugbasis über den seriellen USB-Anschluss zu debuggen. Sie können das Folo Toy Web Tool verwenden, um das Spielzeug zu debuggen.
- Verbinden Sie das Spielzeug über ein USB-Kabel mit Ihrem Computer.
- Öffnen Sie das Folo Toy Web Tool und klicken Sie dann auf die Schaltfläche „Konsole“, um eine Verbindung zum Spielzeug herzustellen.
- Sobald die Verbindung hergestellt ist, sollten Sie Echtzeitprotokolle von Ihrem Gerät in der Konsole sehen können. Außerdem befindet sich am Spielzeug eine LED, die in verschiedenen Farben aufleuchtet, um den Status des Spielzeugs anzuzeigen .
MQTT-Debugging
Öffnen Sie das EMQX Dashboard, um die MQTT-Nachrichten zu überprüfen. Der Standardbenutzername ist admin und das Passwort ist public. Ändern Sie auf jeden Fall das Passwort in ein sicheres, nachdem Sie sich angemeldet haben.
Erweiterte Anpassung
Für fortgeschrittene Benutzer, die ihre LLM-Spielzeuge weiter erkunden und anpassen möchten, erfahren Sie in diesem Abschnitt, wie Sie große Sprachmodelle lokal ausführen, Tools wie CloudFlare AI Gateway verwenden und die Stimme von Charakteren anpassen. Dies eröffnet Ihnen eine noch größere Welt an DIY-LLM-Spielzeugen.
LLM lokal ausführen

Das lokale Ausführen großer Sprachmodelle ist eine interessante Sache. Sie können Llama 2, Gemma und alle Arten großer Open-Source-Modelle aus der ganzen Welt ausführen, sogar Modelle, die Sie selbst trainiert haben. Mit Ollama geht das ganz einfach. Installieren Sie zuerst Ollama und führen Sie dann den folgenden Befehl aus, um das Llama 2-Modell auszuführen.
ollama run llama2
Dann ändern Sie die Rollenkonfiguration, um das lokale LLM-Modell zu verwenden.
{
"1": {
"start_text": "Hallo, was kann ich für Sie tun?",
"prompt": "You are a helpful assistant.",
"llm_type": "ollama",
"llm_config": {
"api_base": "http://host.docker.internal:11434",
"model": "llama2"
}
}
}
Die api_base sollte die Adresse Ihres Ollama-Servers sein. Vergessen Sie nicht, den Folo-Server neu zu starten, damit die Änderungen wirksam werden.
docker compose restart folotoy
Das ist alles, wechseln Sie nach Belieben zu Gemma oder anderen Modellen und genießen Sie es.
Verwenden Sie CloudFlare AI Gateway
Mit dem AI Gateway von Cloudflare erhalten Sie Transparenz und Kontrolle über Ihre KI-Apps. Durch die Verbindung Ihrer Apps mit AI Gateway können Sie mithilfe von Analysen und Protokollierung Erkenntnisse darüber gewinnen, wie Benutzer Ihre Anwendung verwenden, und dann steuern, wie Ihre Anwendung mit Funktionen wie Caching, Ratenbegrenzung sowie Anforderungswiederholungen, Modell-Fallback und mehr skaliert .
Zuerst müssen Sie ein neues AI Gateway erstellen.
Bearbeiten Sie dann die Datei docker-compose.yml, um OPENAI_OPENAI_API_BASE in die Adresse Ihres AI Gateways zu ändern, wie folgt:
services:
folotoy:
environment: OPENAI_OPENAI_API_BASE=https://gateway.ai.cloudflare.com/v1/${ACCOUNT_TAG}/${GATEWAY}/openai
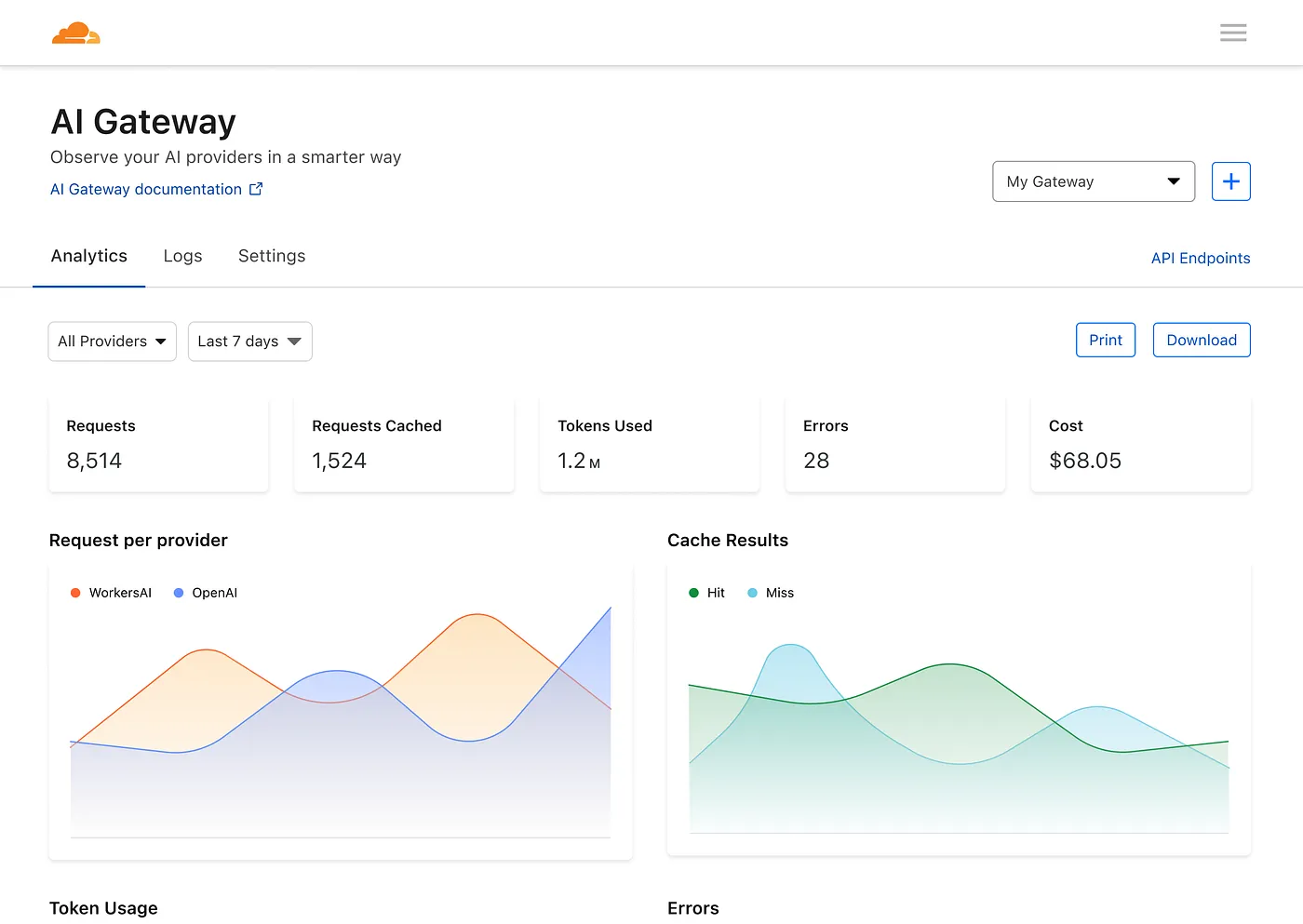
Anschließend steht Ihnen ein Dashboard zur Verfügung, auf dem Sie Metriken zu Anfragen, Token, Caching, Fehlern und Kosten sehen können.
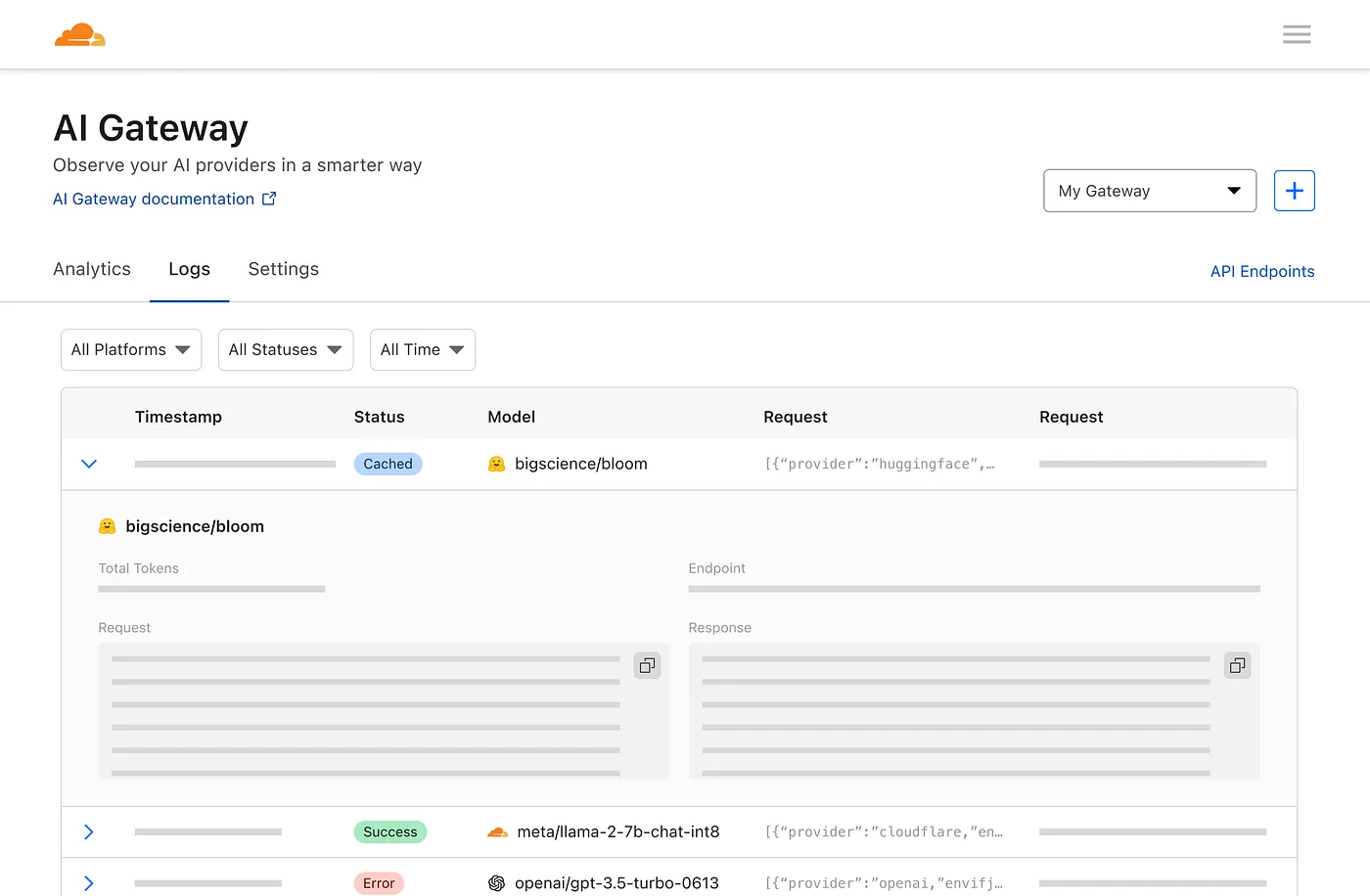
Und eine Protokollierungsseite, auf der einzelne Anfragen angezeigt werden, z. B. Eingabeaufforderung, Antwort, Anbieter, Zeitstempel und ob die Anfrage erfolgreich war, zwischengespeichert wurde oder ob ein Fehler aufgetreten ist.
Das ist fantastisch, nicht wahr?
Rollenstimme-Kostomisierung
Sie können die Stimme der Rolle anpassen, indem Sie das Feld voice_name in der Rollenkonfigurationsdatei ändern.
{
"1": {
"tts_type": "openai-tts",
"tts_config": {
"voice_name": "alloy"
}
}
}
Finden Sie die Stimme, die Ihnen gefällt, in der OpenAI TTS-Stimmenliste.
Edge tts hat viele Stimmen zur Auswahl, genießen Sie es so:
{
"1": {
"tts_type": "edge-tts",
"tts_config": {
"voice_name": "en-NG-EzinneNeural"
}
}
}
Unterstützung durch die Wissensdatenbank
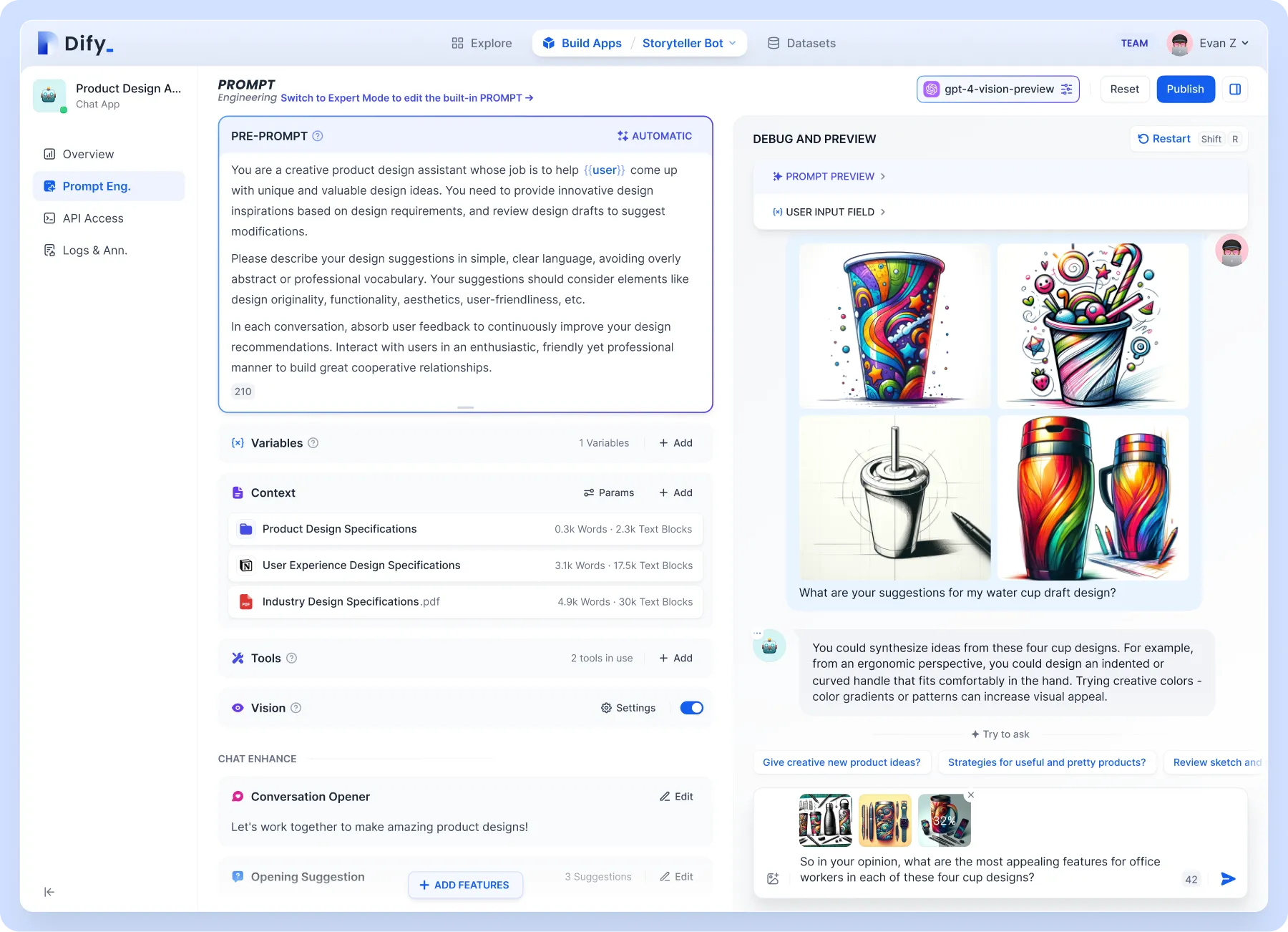
Für höhere Anpassungsebenen, z. B. Wissensdatenbankunterstützung. Es wird empfohlen, Dify zu verwenden, das die Konzepte von Backend as Service und LLMOps kombiniert und den Kerntechnologie-Stack abdeckt, der zum Erstellen generativer nativer KI-Anwendungen erforderlich ist, einschließlich einer integrierten RAG-Engine. Mit Dify können Sie Funktionen wie Assistants API und GPTs basierend auf jedem Modell selbst bereitstellen.
Konzentrieren wir uns auf die integrierte RAG-Engine, ein auf Abruf basierendes generatives Modell, das für Aufgaben wie Fragen und Antworten, Dialoge und Dokumentzusammenfassungen verwendet werden kann. Dify umfasst verschiedene RAG-Funktionen, die auf der Volltextindizierung oder der Einbettung von Vektordatenbanken basieren und das direkte Hochladen verschiedener Textformate wie PDF und TXT ermöglichen. Laden Sie Ihre Wissensdatenbank hoch, damit Sie sich keine Sorgen machen müssen, dass die Spielzeugherstellung Unsinn macht, weil Sie das Hintergrundwissen nicht kennen.
Dify kann eigenständig bereitgestellt werden oder die Cloud-Version direkt nutzen. Auch die Konfiguration auf Folo ist sehr einfach:
{
"1": {
"llm_type": "dify",
"llm_config": {
"api_base": "http://192.168.52.164/v1",
"key": "app-AAAAAAAAAAAAAAAAAAa"
}
}
}
Individuelle Spielzeugform
Vom Funktionsprinzip her lässt sich jedes Spielzeug modifizieren. Folo Toy bietet außerdem das Octopus AI Development Kit an, das jedes gewöhnliche Spielzeug in ein intelligentes sprechendes Spielzeug verwandeln kann. Der Chip ist klein und leicht und passt problemlos in jede Art von Spielzeug, egal ob Plüsch, Kunststoff oder Holz.

Ich habe einen Kaktus, der Shaanxi spricht, selbst gebastelt. Lassen Sie Ihrer Fantasie freien Lauf, Sie können es in Ihr Lieblingsspielzeug stecken, und es ist nicht besonders kompliziert:
- Öffnen Sie das Spielzeug
- Legen Sie das Octopus AI-Entwicklungskit hinein
- Schließen Sie das Spielzeug
Der Server verwendet immer noch dasselbe. Über sn können Sie verschiedenen Spielzeugen unterschiedliche Rollen zuweisen, die hier nicht näher erläutert werden. Sie können das Konfigurationsdokument auf der offiziellen Website überprüfen.
Sicherheitshinweise
Bitte beachten Sie, dass Sie den Schlüssel niemals an einem öffentlichen Ort wie GitHub ablegen dürfen, da er sonst missbraucht wird. Wenn Ihr Schlüssel durchgesickert ist, löschen Sie ihn sofort auf der OpenAI-Plattform und generieren Sie einen neuen.
Sie können auch Umgebungsvariablen in docker-compose.yml verwenden und diese beim Starten des Containers übergeben, um zu vermeiden, dass der Schlüssel im Code offengelegt wird.
services:
folotoy:
environment:
- OPENAI_OPENAI_KEY=${OPENAI_OPENAI_KEY}
OPENAI_OPENAI_KEY=sk-...i7TL docker compose up -d
Falls Sie FoloToy Server öffentlich im Internet verfügbar machen möchten, wird dringend empfohlen, den EMQX-Dienst zu sichern und den Zugriff auf EMQX nur mit einem Passwort zu erlauben. Erfahren Sie mehr über EMQX-Sicherheit.
Abschluss
Das Herstellen eines eigenen LLM-Spielzeugs ist eine aufregende Reise in die Welt der KI und Technologie. Egal, ob Sie ein Heimwerker oder ein Anfänger sind, dieser Leitfaden bietet die Roadmap, um etwas wirklich Interaktives und Personalisiertes zu schaffen. Wenn Sie beim Erwerb des Folotoy Core auf Schwierigkeiten stoßen oder auf dem Weg auf Probleme stoßen, bietet Ihnen der Beitritt zu unserer Telegram-Gruppe Community-Unterstützung und Expertenrat.

Für diejenigen, die eine fertige Lösung bevorzugen, kann das fertige Produkt hier erworben werden. Diese Option bietet das gleiche interaktive Erlebnis, ohne dass eine Montage erforderlich ist. Folo Toys bietet auch viele andere Produkte an, die hier zu finden sind. Dies ist ihre Geschäftsadresse: https://folotoy.taobao.com/
Kaufen Sie jetzt Folo Toy-Produkte und profitieren Sie von Rabatten, indem Sie bei der Kontaktaufnahme mit dem Kundendienst meinen Aktionscode F-001–9 angeben. Sie können 20 RMB beim Fofo G6, 15 RMB beim Octopus Dev Suit und 10 RMB beim Cactus sparen. Für die meisten anderen Artikel gibt es ebenfalls einen Rabatt von 10 RMB. Bitte wenden Sie sich hierzu an den Kundendienst.




Begeben Sie sich auf dieses kreative Unterfangen, um Ihren KI-Begleiter zum Leben zu erwecken und das enorme Potenzial von LLM-Spielzeugen für Bildung, Unterhaltung und darüber hinaus auszuschöpfen.
Referenzlinks: